はじめに
過去の記事で、レシートから合計金額を抽出するOCR処理を作成した。本記事では、過去作成したOCR処理をFastAPIに組み込み、レシート画像から合計金額を抽出するAPIサーバを構築する。
FastAPI
FastAPIは、FlaskやDjangoと同じく、PythonのWebフレームワークである。既存のフレームワークとの違いは、FastAPIの内部でASGI FrameworkのStarletteや、型のバリデーション機能を持つPydanicを利用しており、NodeJsやGo並の高いパフォーマンスが実現できる点であると述べられている。
実際に有志の方が負荷試験を行った結果では、FastAPIがjaprontoに次ぐ2位の性能を達成し、DjangoやFlaskよりもハイパフォーマンスであることが証明されている。1位のjaprontoは2018年以降開発が停止しているので、一般的なPythonのWebフレームワークの中では、現時点ではFastAPIが最も処理性能が高いWebフレームワークであると言えそう。
さらに、FasAPIはドキュメントも充実しており、日本語のドキュメントも一部存在しているため、日本人でも開発もしやすい環境も整っている。
FastAPIで画像ファイルをリクエストするAPIの実装
FastAPIで画像ファイルを扱うAPIを実装するために、FileまたはUploadFileモジュールを利用する。公式ドキュメントによると2つの違いは以下の通り。
File(): byte形式でファイルを受け取り、メモリ上でファイルを扱う。小さいサイズのファイルを扱う場合に利用する。UploadFile(): 非同期処理を実装でき、大いサイズのファイルを受け取り可能。File()と異なり、ファイルのメタデータ(filename,content-type)を利用可能。
上記の内容からも、画像や動画を扱う場合はUploadFile()を利用するのが推奨されている。それ以外のファイル形式の場合も、UploadFile()はFile()と比較して機能が豊富なので、基本的にこちらを利用するのが良さそう。
一方でFile()は、メモリ上でファイルを扱えるので「サイズの小さいテキストやcsvを、メモリ上で高速で処理したい」のような、限られた場面ではFile()を利用する場合も考えられる。
今回は、スマートフォンで撮影した比較的に大きめのサイズの画像を扱うことを想定しているので、UploadFile()を利用してファイルを扱う。
実装
1. 前準備
はじめにFastAPIとuvicornをインストールする。
pip install fastapi==0.75.1 uvicorn==0.15.0
次にpython-multipartをインストールする。このライブラリはUploadFile()を利用する際に必要となる。
pip install python-multipart==0.0.5
2. OCR機能の確認
レシートから合計金額を抽出する処理は、過去の記事で作成したソースコードをそのまま利用する。処理を実行する際は、GoogleVisionAPIを利用可能なサービスアカウントの認証キーが必要になる。下記の記事を参考に、自身の環境に認証キーを準備する。
ReceiptOcrClient.pyのソースコードの全体像import io
import json
import logging
import os
import re
from google.cloud import vision
from google.cloud.vision_v1 import AnnotateImageResponse
logging.basicConfig(format="%(levelname)s:%(message)s", level=logging.DEBUG)
logger = logging.getLogger(__name__)
class ReceiptOcrClient:
def __init__(
self,
credentials_path: str,
horizonal_threshold: int = 15,
):
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = credentials_path
# Instantiates a client
self.client = vision.ImageAnnotatorClient()
self.credentials_path = credentials_path
self.horizonal_threshold = horizonal_threshold
logger.debug(self.__dict__)
def get_payment_amount(self, content: bytes, key_word: str = "合計") -> int:
"""レシートの画像から支払った合計金額を返す。
Args:
content (bytes): OCRを実行するレシート画像
key_word (str, optional): レシート中の「合計金額」を意味する単語. Defaults to "合計".
Returns:
int: 検出された合計金額の値。検出できない場合は-999を返す。
"""
response = self.ocr(target_image=content)
texts = response["textAnnotations"]
max_x, min_y, max_y = 0, 0, 0
for text in texts[1:]:
if key_word in text["description"]:
vertices = [
"({},{})".format(vertex["x"], vertex["y"])
for vertex in text["boundingPoly"]["vertices"]
]
max_x = text["boundingPoly"]["vertices"][1]["x"] # 右上のポイントのXの値
min_y = text["boundingPoly"]["vertices"][0]["y"] # 左上のポイントのYの値
max_y = text["boundingPoly"]["vertices"][3]["y"] # 右下のポイントのYの値
logger.info(
"検出された文字列: {}, 座標: {}".format(
text["description"], ",".join(vertices)
)
)
break
payment_amount = ""
for text in texts[1:]:
target_min_x = text["boundingPoly"]["vertices"][1]["x"] # 左上のポイントのXの値
target_min_y = text["boundingPoly"]["vertices"][0]["y"] # 左上のポイントのYの値
target_max_y = text["boundingPoly"]["vertices"][3]["y"] # 右下のポイントのYの値
if (
abs(target_min_y - min_y) < self.horizonal_threshold
and abs(target_max_y - max_y) < self.horizonal_threshold
and target_min_x - max_x > 0 # 合計の文字より右にある文字の場合
):
logger.info(f"key_wordと同じ座標にある文字: {text['description']}")
payment_amount += text["description"]
payment_amount = re.sub(r"[¥,.]", "", payment_amount) # 「¥」は無視
logger.info(f"数字情報に再構成: {payment_amount}")
try:
return int(payment_amount)
except ValueError:
logger.error("レシートから合計金額を検出できませんでした。")
return -999
except:
logger.error("実行中にエラーが発生しました。")
return -999
def get_payment_amount_from_filename(
self, file_name: str, key_word: str = "合計"
) -> int:
"""レシートの画像から支払った合計金額を返す。
Args:
file_name (str): OCRを実行する画像ファイルのパス。
key_word (str, optional): レシート中の「合計金額」を意味する単語. Defaults to "合計".
Returns:
int: 検出された合計金額の値。検出できない場合は-999を返す。
"""
# Loads the image into memory
with io.open(file_name, "rb") as image_file:
content: bytes = image_file.read()
return self.get_payment_amount(content=content, key_word=key_word)
def ocr(self, target_image: bytes) -> dict:
"""file_nameに指定した画像に対して、CloudVisionAPIのOCR処理を実行する。
Args:
target_image (bytes): OCRを実行する画像。
Returns:
dict: _description_
"""
image = vision.Image(content=target_image)
response = self.client.document_text_detection(image=image)
return json.loads(AnnotateImageResponse.to_json(response))
if __name__ == "__main__":
import argparse
# 引数の設定
parser = argparse.ArgumentParser()
parser.add_argument(
"target_img",
help="OCR対象の画像のパス",
)
parser.add_argument(
"--credential_path",
help="GoogleCloudVisionAPIを利用する場合のサービスアカウントの認証情報。",
default="config/service_account_key.json",
)
parser.add_argument(
"--horizonal_threshold",
help="キーワードと合計金額の水平位置のズレを、何pxまで許容するかの閾値",
default=15,
type=int,
)
args = parser.parse_args()
# OCRクライアントの初期化
receipt_ocr_client = ReceiptOcrClient(
args.credential_path,
horizonal_threshold=args.horizonal_threshold,
)
# OCRの実行
amount = receipt_ocr_client.get_payment_amount_from_filename(
file_name=os.path.abspath(args.target_img)
)
logger.info(f"合計金額は{amount}円です!")
動作確認として、レシートのサンプル画像(sample.png)に対して処理を実行する。処理結果から、レシート画像に記載されている合計金額が、正しく抽出されていることが確認できる。
$ python ReceiptOcrClient.py sample.png INFO:検出された文字列: 合計, 座標: (16,377),(87,376),(87,386),(16,387) INFO:key_wordと同じ座標にある文字: ¥ INFO:key_wordと同じ座標にある文字: 1 INFO:key_wordと同じ座標にある文字: , INFO:key_wordと同じ座標にある文字: 161 INFO:数字情報に再構成: 1161 INFO:合計金額は1161円です!

sample.png)
次にこの機能をFastAPIに組み込み、OCR処理を実行可能なAPIサーバを構築する。
3. APIサーバにOCR機能の組み込み
先ほど作成したReceiptOcrClient.pyのOCRの処理を実行するエンドポイントを、FastAPIを利用してmain.pyのファイル名で実装する。/api/receiptOcrエンドポイントにPostで送信した場合に、OCR処理が実行されるようにする。
import base64 from typing import List from fastapi import FastAPI, UploadFile from pydantic import BaseModel from ReceiptOcrClient import ReceiptOcrClient class OcrResult(BaseModel): filename: str amount_value: int class OcrResults(BaseModel): results: List[OcrResult] = [] app = FastAPI() receiptOcrClient = ReceiptOcrClient(credentials_path="config/service_account_key.json") @app.post("/api/receiptOcr", response_model=OcrResults) async def create_upload_files(files: List[UploadFile]): response = OcrResults() for file in files: try: data = await file.read() # アップロードされた画像をbytesに変換する処理 bin_data: bytes = base64.b64encode(data).decode() amount: int = receiptOcrClient.get_payment_amount( content=bin_data, key_word="合計" ) ocr_result = OcrResult(filename=file.filename, amount_value=amount) response.results.append(ocr_result) except Exception as e: print(e) return response
下記のコマンドで、Webサーバーを起動する。
uvicorn main:app --reload
実行が完了すると、下記のエンドポイントが起動する。
FasAPIでは、特に設定をしなくても、デフォルトでSwaggerUIが起動するようになっている。下記のURLでSwaggerUIにアクセスできる。
4. 動作確認
動作確認をSwaggerUI上で行う。はじめに下記のURLにアクセスし、SwaggerUIの画面を表示する。
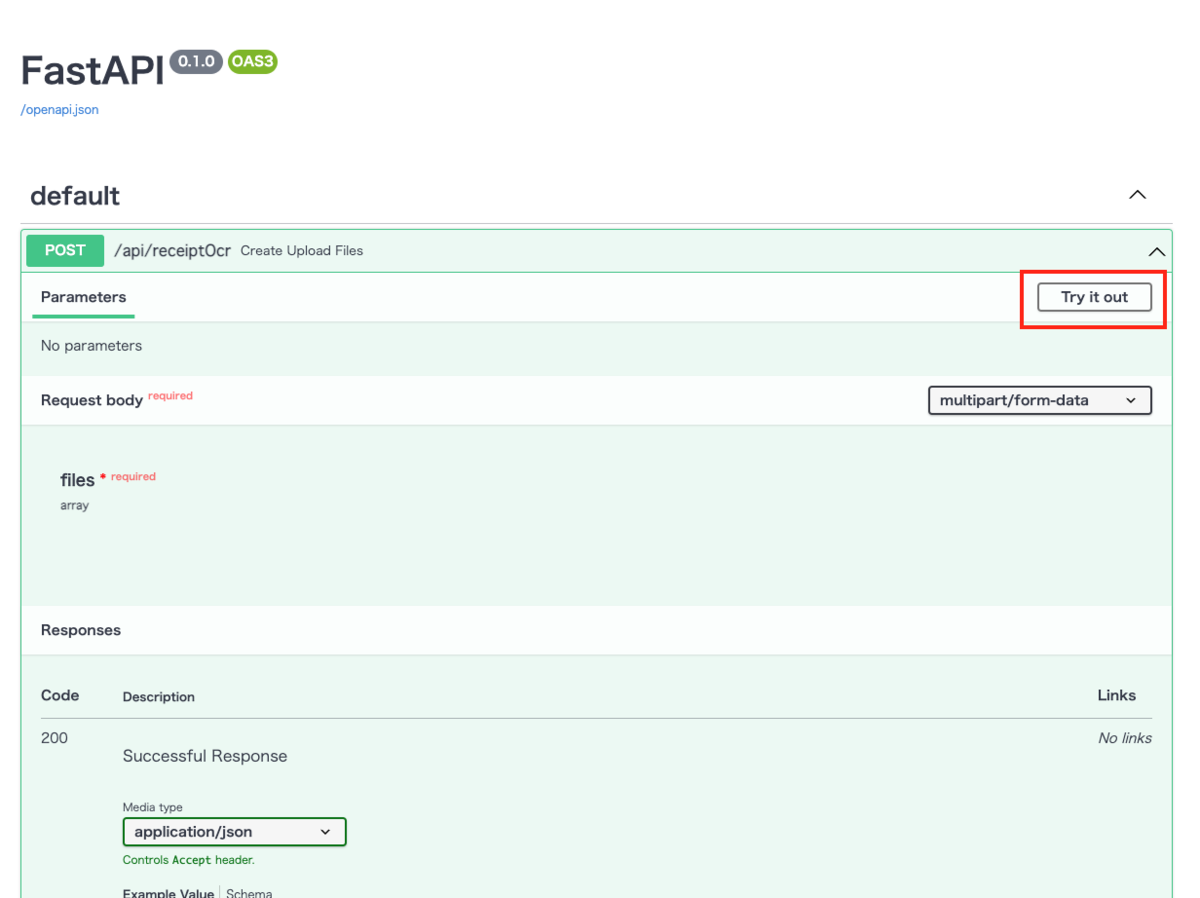
その後、画像中の赤枠を押下しAPIのテスト実行モードに切り替える。その後、「ファイルを選択」の箇所にOCRしたいレシートの画像をドラッグするか、「ファイルを選択」ボタンを押下し対象の画像を選択し、「Execute」を押下する。
処理対象のレシートの画像は、「2. OCR機能の確認」で利用したサンプルのレシート画像を用いる。

画像中赤枠の箇所を確認し、レシートに記載されている合計金額が、レスポンスに含まれていることを確認できた。
SwaggerUIのみでなく、curlでもOCR処理を実行できる。
$ curl -X 'POST' \ 'http://127.0.0.1:8000/api/receiptOcr' \ -H 'accept: application/json' \ -H 'Content-Type: multipart/form-data' \ -F 'files=@sample.jpg;type=image/jpeg' # ↓実行結果 {"results":[{"filename":"sample.jpg","amount_value":1161}]}
おわりに
FastAPIを利用して、簡単に画像を扱うAPIの構築ができた。今回初めてFastAPIを利用したが、ドキュメントが非常にわかりやすく、実装で困ることがほとんどなかった。公式ドキュメントにはMicrosoftやNetflixのエンジニアからのコメントがあったり、最近話題のフレームワークなので、今後の動向が楽しみです。